Intro
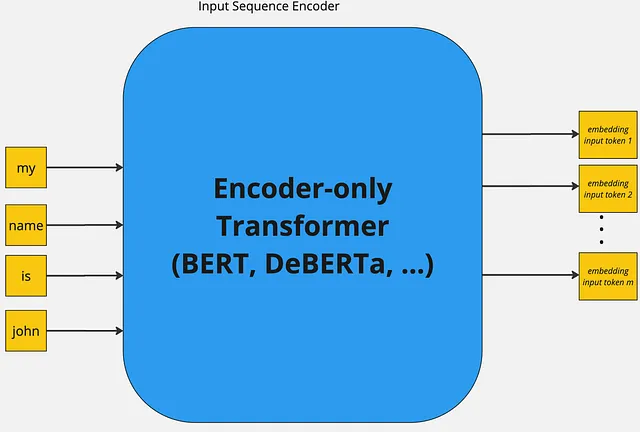
GLiNER (Generalist and Lightweight Model for Named Entity Recognition) is a Named Entity Recognition (NER) model capable of identifying any entity type using a bidirectional transformer encoder (BERT-like). It provides a practical alternative to traditional NER models, which are limited to predefined entities, and Large Language Models (LLMs) that are costly and large for resource-constrained scenarios.
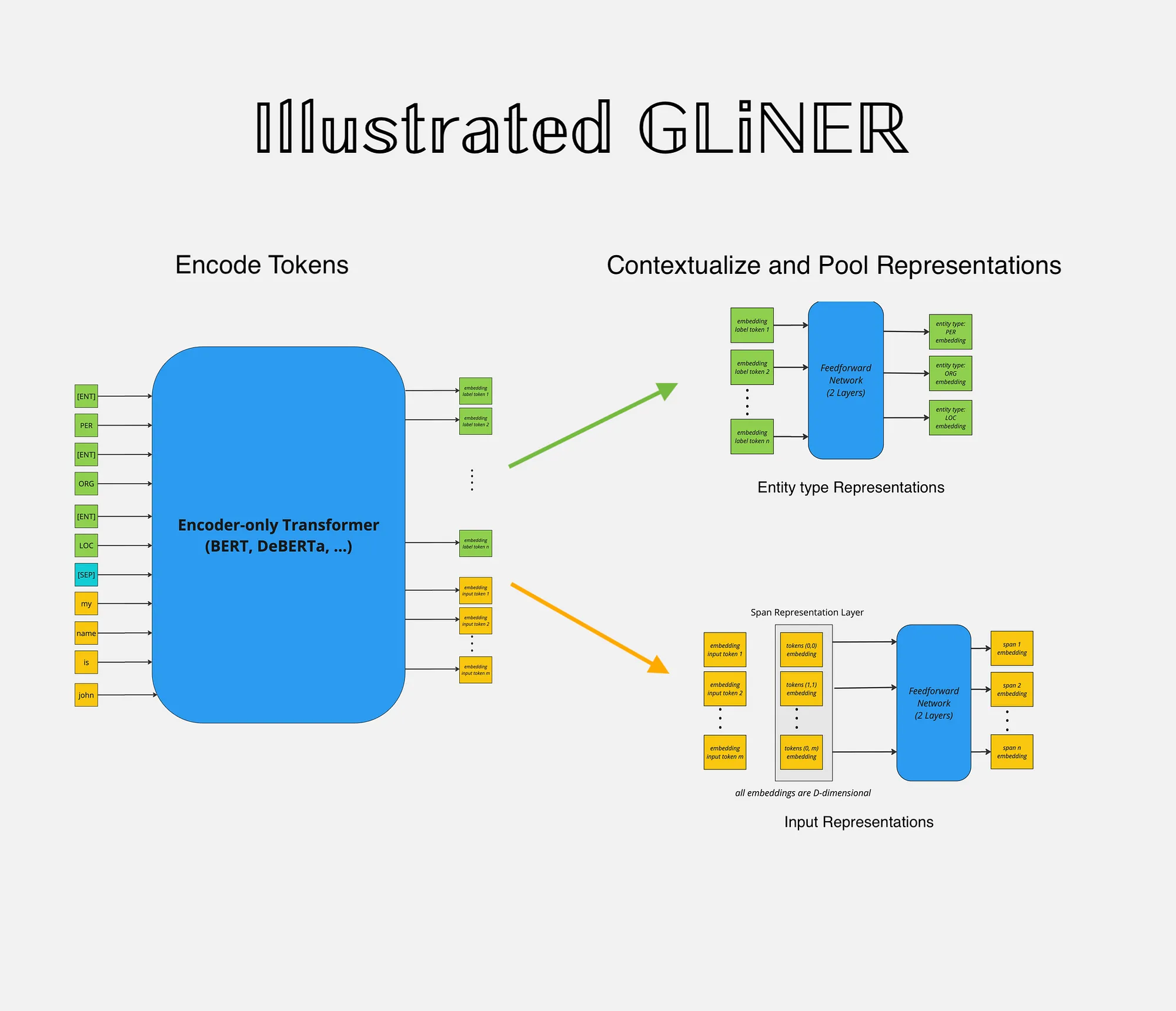
GLiNER equips compact encoder-only models with zero-shot capabilities, making them competitive alternatives to decoder-only LLMs in production settings while offering significant cost and computation savings.
Knowledgator Architectures
Knowledgator has developed three major architectural extensions to GLiNER, each addressing specific limitations and use cases:
1. Bi-encoder GLiNER
Decouples text and label encoding for efficient processing of large entity type sets (50-200+ types). Enables pre-computing and caching label embeddings for faster inference.
Variants: BiEncoderSpan, BiEncoderToken
2. GLiNER-decoder
Adds generative capabilities for open-vocabulary entity labeling. The model generates entity type labels rather than classifying from predefined types.
Variants: UniEncoderSpanDecoder, UniEncoderTokenDecoder
3. GLiNER-relex
Extends GLiNER for joint entity and relation extraction, identifying both entities and relationships in a single forward pass.
Variants: UniEncoderSpanRelex, UniEncoderTokenRelex
Each architecture supports both span-level (standard entities, max length 12 tokens) and token-level (long-form entities, no length limit) variants.
Foundation: Vanilla GLiNER
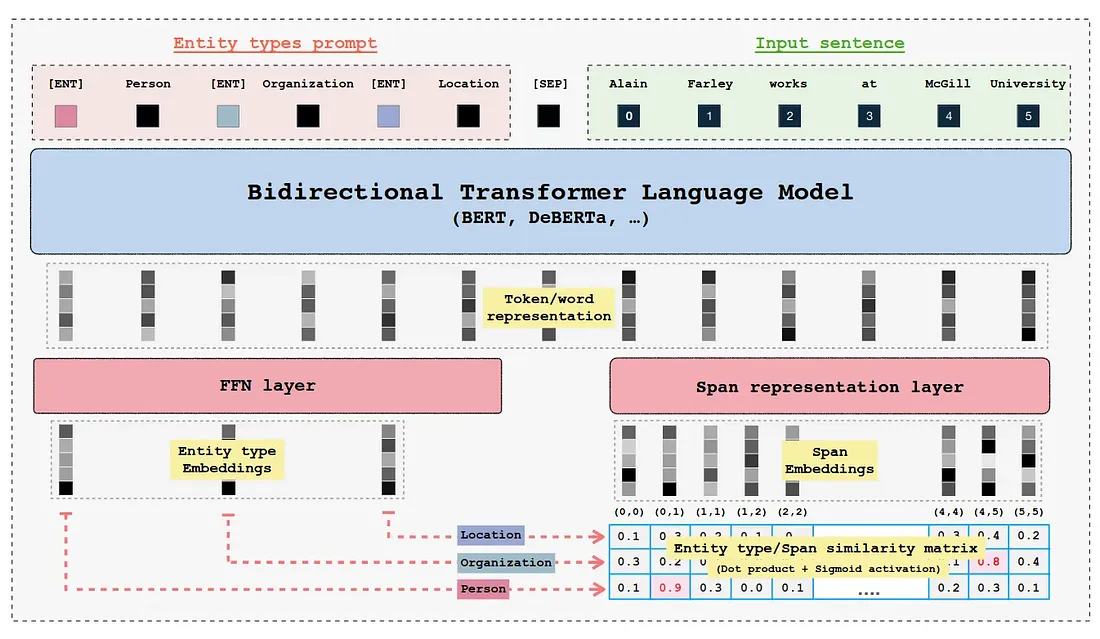
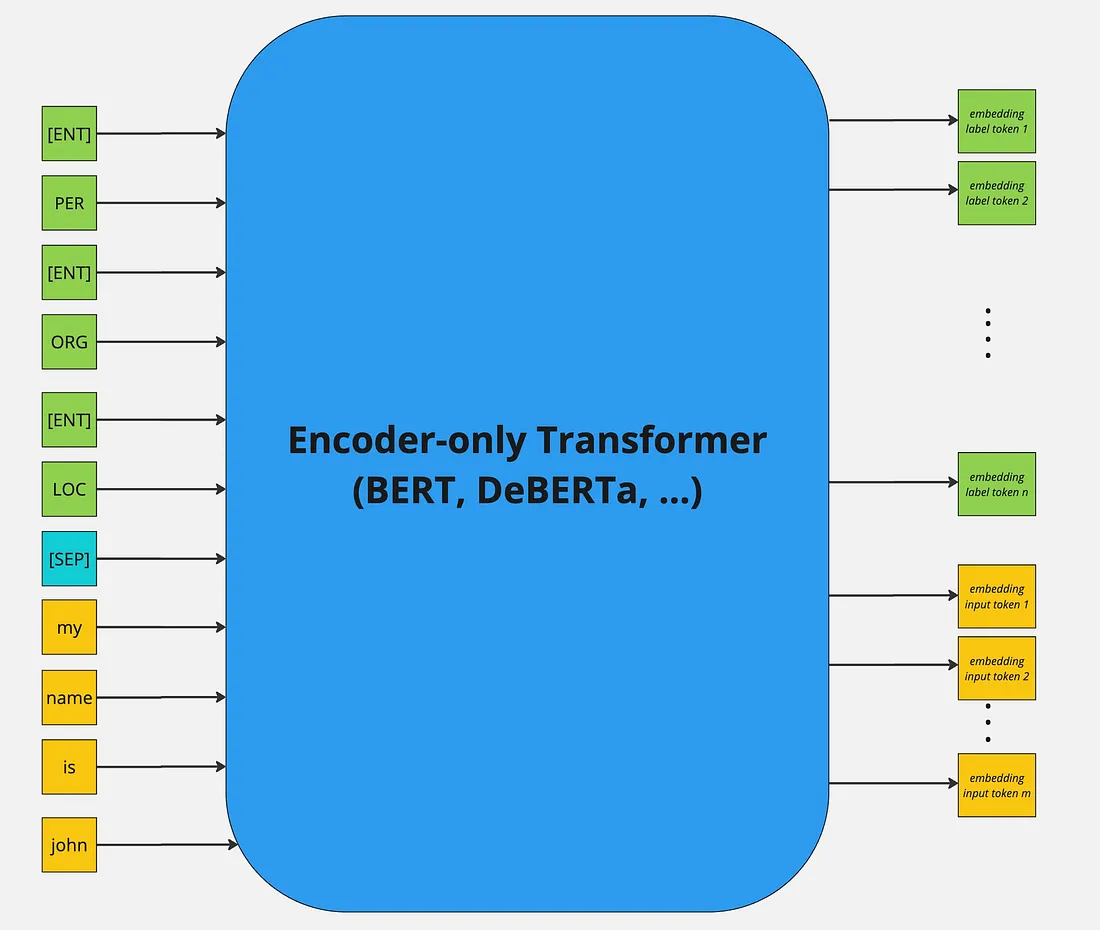
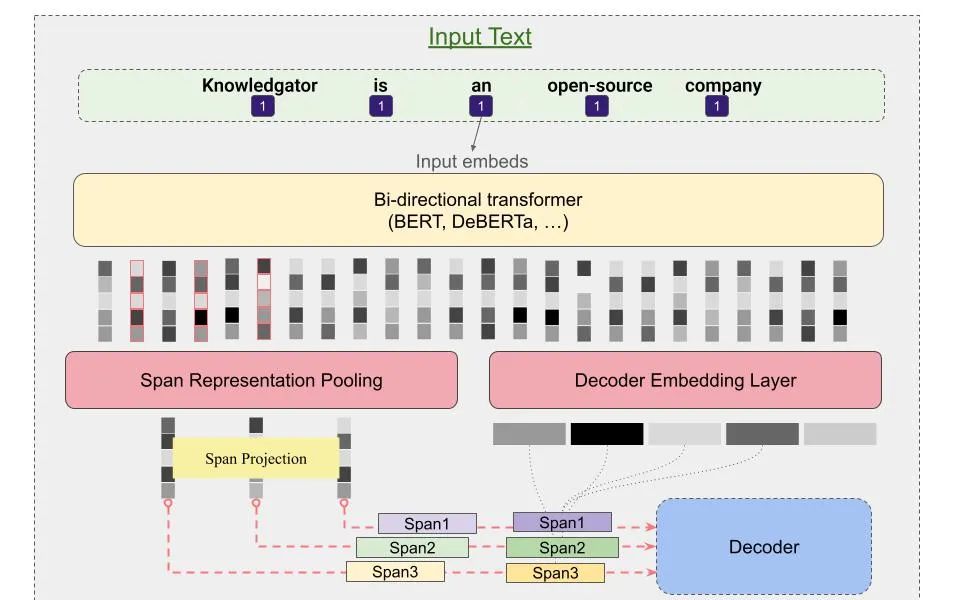
The original GLiNER architecture uses a BERT-like encoder with concatenated entity labels and input text, separated by [SEP] tokens. Each entity type is preceded by a special [ENT] token.
Key components:
- Entity labels and text are jointly encoded
[ENT]token representations capture entity types (refined via FFN)- Text tokens are combined into spans (max length: 12)
- Span-label compatibility computed via dot product + sigmoid
- Binary cross-entropy loss for training
Span representation: For span from token i to j, representations combine start/end tokens with span width features.
![]()
Decoding: Threshold interaction scores, then select highest-scoring non-overlapping spans (Flat NER) or allow overlaps (Nested NER).
Limitation: Performance degrades with >30 entity types due to joint encoding overhead.
Foundation: GLiNER Multi-task
GLiNER Multi-task extends the original architecture to handle long-form extraction tasks (summarization, question-answering, relation extraction) by using token-level predictions instead of spans.
Key differences from Vanilla GLiNER:
- Uses BIO tagging (start, inside, end) instead of span enumeration
- No maximum entity length limitation
- Bi-directional LSTM added after encoding for stability
- Token representations projected to higher-dimensional space (2x)

Architecture: Token and label representations are element-wise multiplied and concatenated, then passed through FFN to generate three logits per token-label pair (start, inside, end).
Self-training: Model generates weak labels, then fine-tunes on them using label smoothing for regularization.
GLiNER Bi-encoder (Knowledgator)
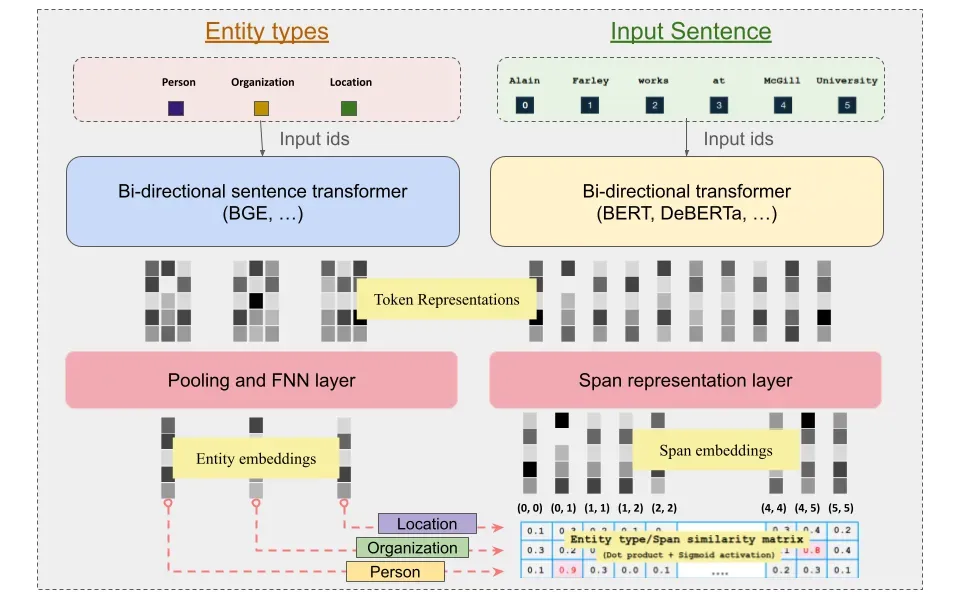
The bi-encoder architecture addresses three key limitations of vanilla GLiNER:
- Performance degradation with >30 entity labels
- Computational overhead when encoding many entity types with short input sequences
- Entity representations conditioned on positional order
Architecture
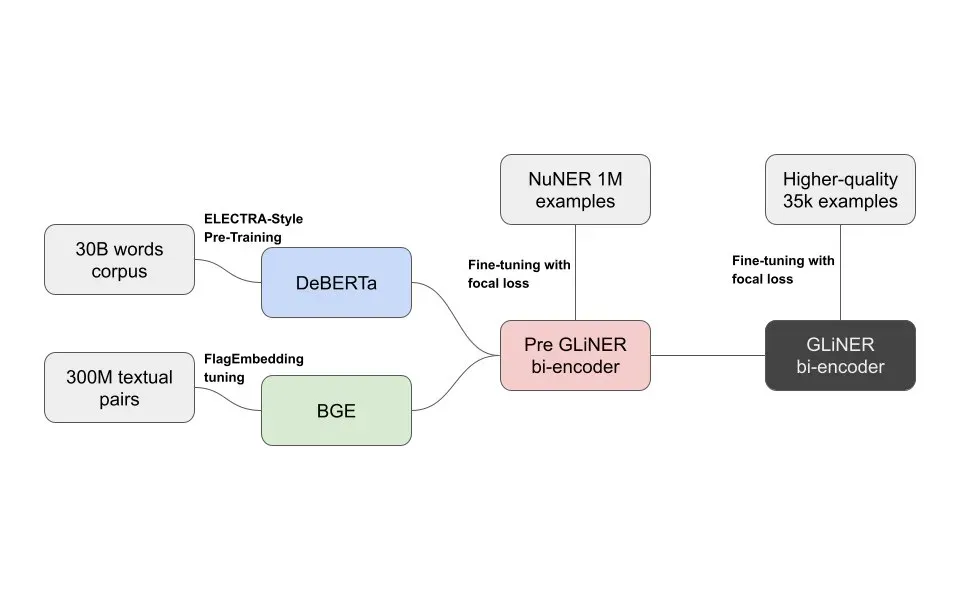
The bi-encoder decouples text and label encoding into separate models:
- Text encoder: DeBERTa processes input sequences
- Label encoder: BGE (sentence transformer) processes entity types
- Poly-encoder: Fuses representations to capture text-label interactions
This enables pre-computing label embeddings once and reusing them across batches, significantly improving efficiency for large entity type sets (50-200+).
Variants
- BiEncoderSpan: Span-level predictions for standard NER tasks
- BiEncoderToken: Token-level BIO tagging for long-form entities
Training
Two-stage training on pre-trained DeBERTa and BGE models:
- Pre-train on 1M NER samples to align label and span representations
- Fine-tune on 35k high-quality samples to refine task performance
Focal loss mitigates class imbalance from large batch sizes:
![]()
Where α controls positive/negative sample influence and γ down-weights easy examples to focus on hard samples.
Key Advantages
- Handle 50-200+ entity types without performance degradation
- Pre-compute and cache label embeddings for faster inference
- Improved zero-shot robustness on out-of-distribution data
- Ideal for production deployment with fixed schemas
GLiNER-decoder (Knowledgator)
 GLiNER-decoder adds generative capabilities for open-vocabulary entity labeling, enabling the model to generate entity type labels rather than classify from predefined types.
GLiNER-decoder adds generative capabilities for open-vocabulary entity labeling, enabling the model to generate entity type labels rather than classify from predefined types.
Architecture
Combines GLiNER span/token detection with a GPT-2 decoder:
- Entity detection: Standard GLiNER encoder detects entity boundaries
- Generative decoder: GPT-2 generates natural language labels for detected entities
Operating modes:
- Prompt mode: Decoder generates labels that replace predefined types
- Span mode: Decoder generates labels as additional information alongside predicted types
Variants
- UniEncoderSpanDecoder: Span-based detection with label generation
- UniEncoderTokenDecoder: Token-level BIO tagging with label generation
Training
Multi-objective loss with adjustable coefficients:
- Span/token classification loss for entity detection
- Cross-entropy loss for decoder label generation
Use Cases
- Open-domain NER with unknown entity types
- Fine-grained entity typing beyond predefined categories
- Zero-shot label discovery based on context
- Long-form entity extraction with descriptive labels (token variant)
Example
from gliner import GLiNER
model = GLiNER.from_pretrained("knowledgator/gliner-decoder-small-v1.0")
text = "Apple Inc. was founded by Steve Jobs in Cupertino."
entities = model.inference(
[text],
labels=["entity"], # Generic prompt
gen_constraints=["company", "person", "location"],
num_gen_sequences=1
)
GLiNER-relex (Knowledgator)
GLiNER-relex extends GLiNER for joint entity and relation extraction, identifying both entities and relationships between them in a single forward pass.
Architecture
Three main components:
- Entity span/token encoder: Detects entity boundaries
- Relation representation layer: Computes pairwise entity representations and adjacency predictions
- Relation classification layer: Classifies relation types between entity pairs
Special tokens:
[ENT]: Entity type marker[REL]: Relation type marker[SEP]: Separator between entity types, relation types, and text
Variants
- UniEncoderSpanRelex: Span-based entity detection with relations
- UniEncoderTokenRelex: Token-level entity detection with relations (no span length limits)
Training
Multi-task loss with three components:
- Span/token loss: Entity boundary detection
- Adjacency loss: Entity pair connectivity
- Relation loss: Multi-label classification for relation types
Use Cases
- Knowledge graph construction from text
- Information extraction with entity-relation structures
- Document understanding for structured data extraction
- Scientific literature processing (long entities with relations)
Example
from gliner import GLiNER
model = GLiNER.from_pretrained("knowledgator/gliner-relex-large-v0.5")
text = "John Smith works at Microsoft in Seattle."
entity_labels = ["person", "organization", "location"]
relation_labels = ["works_at", "located_in"]
entities, relations = model.inference(
[text],
labels=entity_labels,
relations=relation_labels,
threshold=0.5
)
Output format:
Entities follow standard GLiNER format. Relations include head/tail entity references:
{
'head': {'text': 'John Smith', 'type': 'person', 'entity_idx': 0},
'tail': {'text': 'Microsoft', 'type': 'organization', 'entity_idx': 1},
'relation': 'works_at',
'score': 0.87
}
References
- The Intro section is based on the Shahrukh Khan article Illustrated GLINER and placed into documentation with consent of the author.
- Urchade Zaratiana, Nadi Tomeh, Pierre Holat, and Thierry Charnois. 2023. Gliner: Generalist model for named entity recognition using bidirectional transformer
- Ihor Stepanov, and Mykhailo Shtopko. 2024. GLINER MULTI-TASK: GENERALIST LIGHTWEIGHT MODEL FOR VARIOUS INFORMATION EXTRACTION TASKS
- Meet the new zero-shot NER architecture | by Knowledgator Engineering | Aug, 2024 | Medium